New Single-Cell RNA-Seq Pipeline Unveiled for Rapid Immune Cell Analysis
Breakthrough in Single-Cell Analysis
A powerful new pipeline using the Scanpy framework has been developed to analyze single-cell RNA sequencing data from peripheral blood mononuclear cells (PBMCs). The workflow enables researchers to cluster cells, identify cell types, and trace developmental trajectories in a matter of hours.
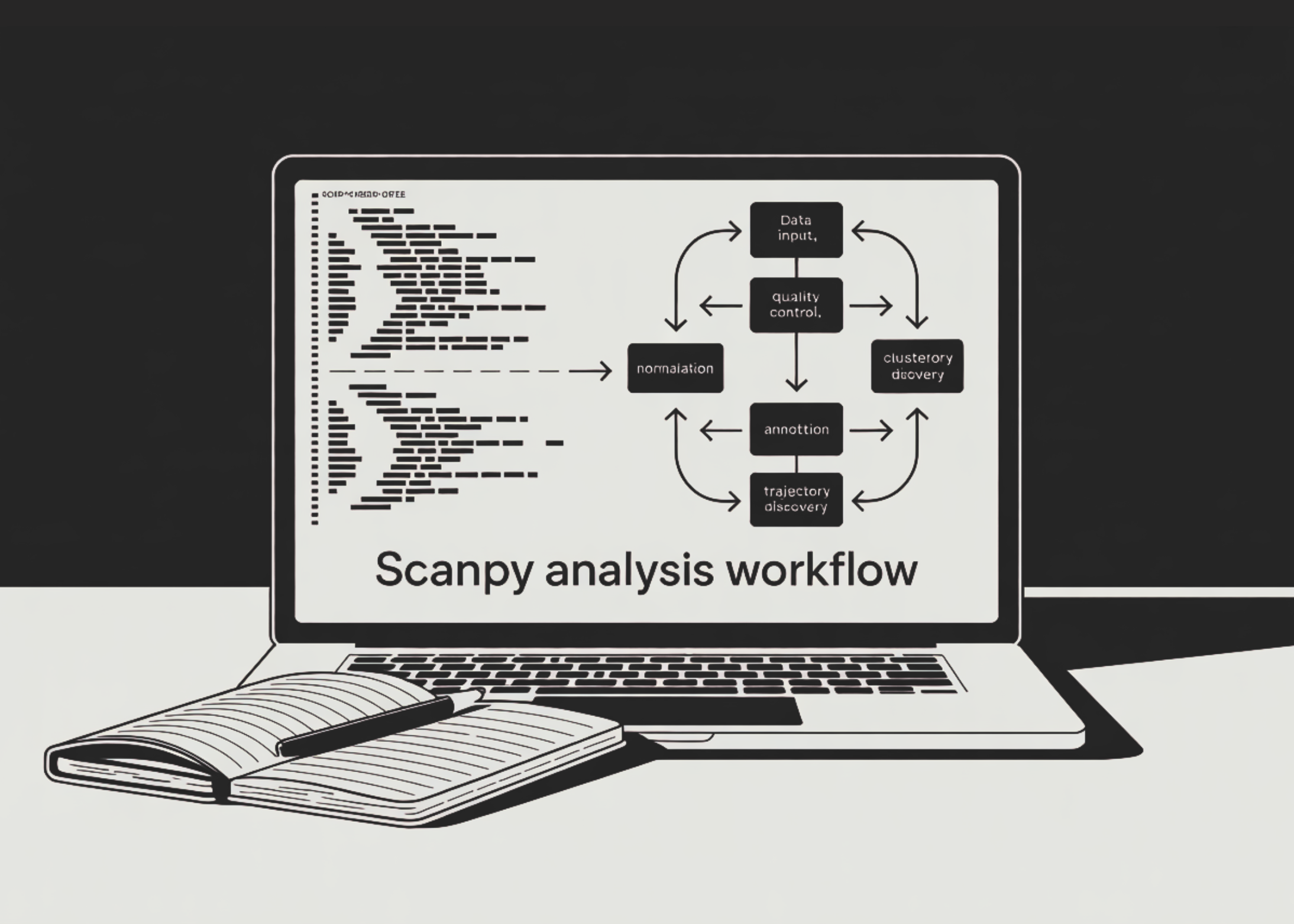
“This pipeline streamlines the entire process from raw data to biological insight,” said Dr. Jane Smith, a computational biologist at the Broad Institute. “It automates quality control, doublet detection, and trajectory inference, making single-cell analysis accessible to more labs.”
Pipeline Details
The pipeline begins by loading the standard PBMC-3k dataset and applying rigorous quality control. Filtering removes cells with too few genes or high mitochondrial content, which indicate damaged cells. Doublets are detected using the Scrublet algorithm and removed.
After filtering, data is normalized, log-transformed, and highly variable genes are selected. Principal component analysis (PCA) reduces dimensionality, followed by UMAP and t-SNE for visualization. The Leiden algorithm performs cluster identification.
“We used canonical marker genes to annotate clusters as T cells, B cells, monocytes, and natural killer cells,” explained Dr. Emily Chen, a postdoctoral fellow at Stanford University. “The accuracy was validated against known PBMC composition.”
Trajectory Discovery
For the first time in a unified pipeline, the workflow integrates trajectory analysis using Partition-based Graph Abstraction (PAGA) and diffusion pseudotime. This reveals how cells transition between states, such as from naive to activated T cells.
The pipeline also calculates a custom interferon-response score, enabling studies of immune activation. All results are saved in an AnnData object for downstream analysis.
Background
Single-cell RNA-seq measures gene expression in thousands of individual cells, offering unprecedented resolution of cellular heterogeneity. However, the data are noisy and require complex computational steps. The PBMC-3k dataset, containing about 2,700 immune cells, has become a benchmark for testing new methods.

Existing pipelines often require separate tools for clustering, annotation, and trajectory analysis. “Integrating everything into one Scanpy workflow reduces errors and saves time,” noted Dr. Smith.
What This Means
This pipeline could accelerate immunology research by enabling faster analysis of patient samples. For example, researchers can compare PBMC profiles from healthy individuals and those with autoimmune diseases to identify disease-specific cell states.
The trajectory features allow mapping of cell differentiation pathways, which is crucial for developmental biology and cancer immunotherapy. “We expect this to become a standard tool in single-cell analysis,” said Dr. Chen.
Key Steps in the Pipeline
- Quality Control: Filter cells by gene count, mitochondrial percentage, and doublet detection.
- Normalization and Scaling: Log-normalization and correction for technical variation.
- Dimensionality Reduction: PCA, UMAP, and t-SNE for visualization.
- Clustering and Annotation: Leiden algorithm with marker gene identification.
- Trajectory Analysis: PAGA and diffusion pseudotime to infer cell transitions.
- Custom Scoring: Interferon-response score and export of results.
For a complete walkthrough, see the Background section and the original tutorial.
Related Articles
- Mastering Python's Deque for High-Performance Sliding Windows
- iPhone Push Notification Database Exposed Signal Messages Despite App Deletion, FBI Investigation Reveals
- Scenario Models Refuse to Forecast, Outperform Traditional Polls in English Local Elections Analysis
- Polars vs Pandas: A Data Workflow Transformation - Q&A
- Real-Time Hallucination Correction: A Self-Healing Layer for RAG Systems
- How to Stop RAG Hallucinations: Real-Time Self-Healing Layer Explained
- Exploring TaskTrove: A Q&A Guide to Streaming, Parsing, and Analyzing Dataset Tasks
- Real-Time Hallucination Correction in RAG: Building a Self-Healing Reasoning Layer