KernelEvolve Q&A: Optimizing AI Kernels Across Heterogeneous Hardware at Meta
Welcome to the second installment of our series on Meta's Ranking Engineer Agent, an autonomous AI that accelerates ads ranking innovation. This article focuses on the critical low-level infrastructure that powers high-performance model execution. We explore KernelEvolve, an intelligent agent that automates the creation and optimization of custom kernels—the chip-specific instructions that translate model operations into efficient computations. KernelEvolve tackles the challenge of supporting a diverse fleet of hardware, including NVIDIA and AMD GPUs, Meta's custom MTIA chips, and CPUs, by treating kernel optimization as a search problem. Below, we answer common questions about how KernelEvolve works, its benefits, and its impact on Meta's AI infrastructure.
What is KernelEvolve and why was it created?
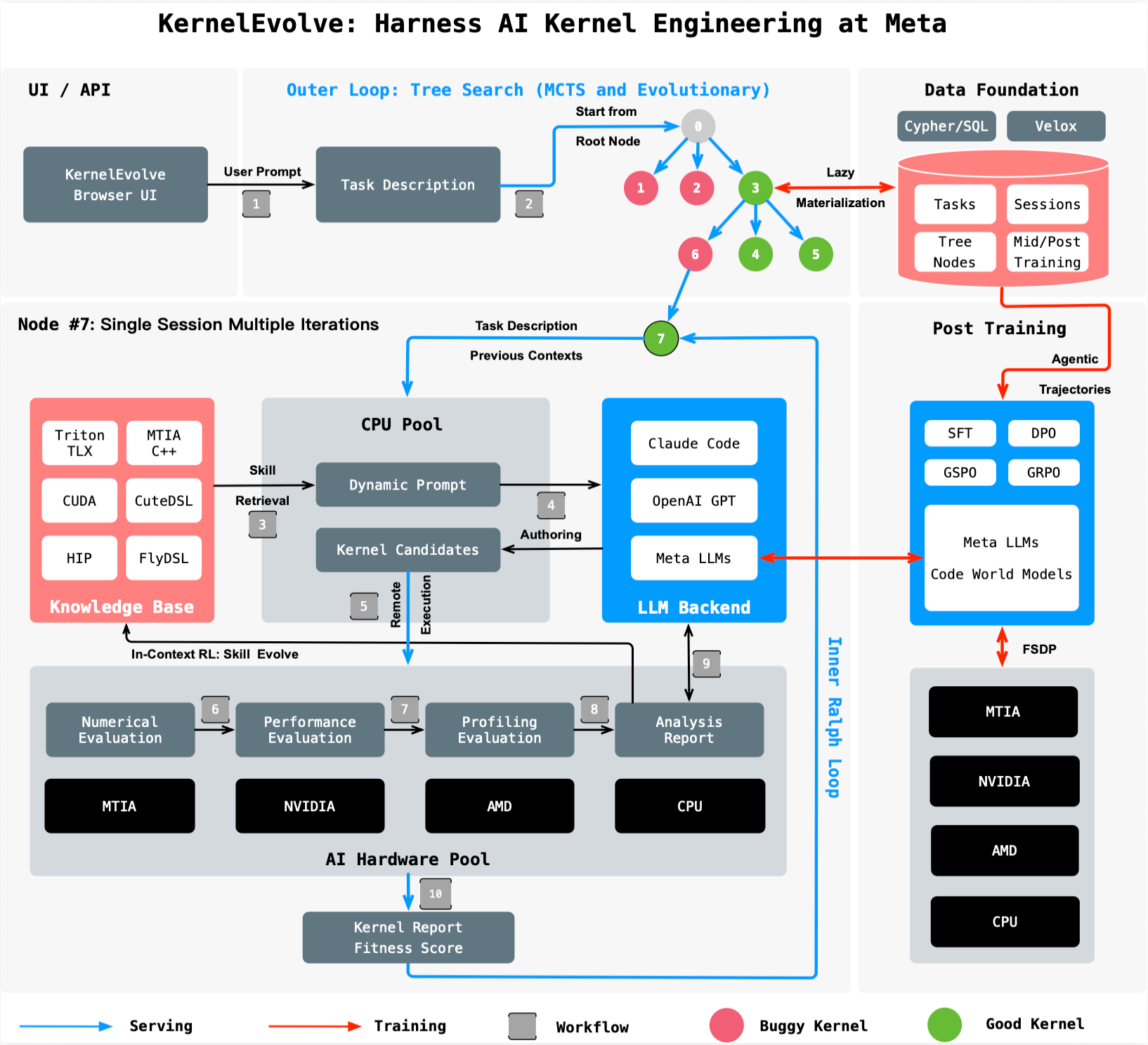
KernelEvolve is an agentic system developed by Meta to automate the authoring and optimization of low-level kernel code for AI models. It was created because Meta operates a massive, heterogeneous fleet of hardware—NVIDIA GPUs, AMD GPUs, Meta's custom MTIA silicon, and CPUs—each requiring chip-specific instructions to run models efficiently. Traditionally, kernel experts spent weeks manually profiling, optimizing, and debugging kernels for each new chip generation and model architecture. With the explosion of model variety and hardware types, this hand-tuning approach no longer scales. KernelEvolve treats optimization as a search problem, using a job harness to evaluate candidate kernels, feed diagnostics back to a large language model (LLM), and iteratively search over hundreds of alternatives. It compresses weeks of expert work into hours, enabling faster development and freeing engineers to focus on higher-level innovation.
Why is custom kernel optimization essential for Meta's AI workloads?
Meta's AI workloads, from personalized recommendations to generative AI assistants, must run at massive scale on a diverse hardware infrastructure. While vendor libraries provide standard kernels for common operations like GEMMs and convolutions, production ranking models require many custom operators that are not covered by these libraries. Each new chip generation and ML model architecture demands optimized kernels to fully utilize hardware capabilities. Without custom optimization, performance suffers, leading to slower inference and training, higher latency, and increased energy consumption. KernelEvolve addresses this by automatically generating kernels that outperform human-written code, delivering up to 60% inference throughput improvement on NVIDIA GPUs for the Andromeda ads model and over 25% training throughput improvement on Meta's MTIA chips. This optimization is critical for maintaining real-time user experiences and controlling infrastructure costs.
How does KernelEvolve work under the hood?
KernelEvolve frames kernel optimization as a search problem rather than a manual tuning process. The system consists of a purpose-built job harness that takes a candidate kernel—generated by an LLM or from a template—and evaluates its performance on target hardware. After profiling, the harness collects detailed diagnostics such as execution time, memory bandwidth, and register usage. These diagnostics are fed back to the LLM, which proposes modifications to the kernel code. This loop repeats over hundreds of iterations, exploring a large design space of transformations such as loop tiling, memory coalescing, and instruction scheduling. The search is guided by a reward function that prioritizes throughput and latency. By automating this iterative process, KernelEvolve consistently discovers kernels that exceed the performance of hand-tuned versions written by human experts, all within hours instead of weeks.
What performance improvements has KernelEvolve achieved in production?
KernelEvolve has demonstrated significant gains across Meta's production AI models. For the Andromeda ads model running on NVIDIA GPUs, it achieved over 60% inference throughput improvement compared to baseline kernels. On Meta's custom MTIA silicon chips, it delivered over 25% training throughput improvement for an ads model. These improvements are not isolated—KernelEvolve consistently generates kernels that beat human expert performance across diverse hardware types and model architectures. The system also accelerates the development cycle, compressing weeks of manual kernel engineering into hours of automated search and evaluation. This frees up engineers to work on higher-level model innovations rather than low-level hardware optimizations. Additionally, the generated kernels are cross-validated across different silicon revisions, ensuring reliability and consistency.
Which hardware platforms does KernelEvolve support?
KernelEvolve is designed for broad applicability across Meta's heterogeneous fleet. It supports both public and proprietary hardware, including NVIDIA GPUs, AMD GPUs, Meta's custom MTIA chips, and CPUs. The system is hardware-agnostic in its search methodology, but it tailors kernels to the specific instruction sets and memory hierarchies of each platform. For example, on NVIDIA GPUs, it can generate CUDA kernels; on AMD GPUs, HIP kernels; and on MTIA chips, MTIA C++ kernels. It also works with high-level domain-specific languages (DSLs) like Triton, Cute DSL, and FlyDSL, which abstract away some hardware details while still allowing chip-specific optimizations. This flexibility ensures that as Meta introduces new hardware generations, KernelEvolve can rapidly produce optimized kernels without requiring manual porting efforts by experts.
What programming languages and DSLs are used by KernelEvolve?
KernelEvolve generates kernels in both low-level and high-level languages to target various hardware backends. For maximum performance on NVIDIA GPUs, it produces CUDA code; for AMD GPUs, HIP code; and for Meta's MTIA chips, MTIA C++. To balance productivity and control, it also leverages domain-specific languages (DSLs) such as Triton, Cute DSL, and FlyDSL. These DSLs allow developers to express kernel operations at a higher abstraction level while still enabling compiler-time optimizations. The LLM within KernelEvolve is trained to translate model operations into efficient implementations in these languages, using feedback from the job harness to refine its output. This multi-language capability ensures that KernelEvolve can optimize kernels for any current or future hardware in Meta's fleet, making it a future-proof solution for scaling AI infrastructure.
How does KernelEvolve fit into Meta's broader Ranking Engineer Agent ecosystem?
KernelEvolve is a core component of Meta's Ranking Engineer Agent, an autonomous AI system that accelerates ads ranking innovation. The first post in this series covered the agent's ML exploration capability, which autonomously designs and runs model experiments. KernelEvolve complements this by optimizing the low-level infrastructure that makes those models execute efficiently at scale. When the ranking agent identifies a promising model architecture, KernelEvolve automatically generates and tunes the kernels needed to run it on Meta's diverse hardware fleet. This end-to-end automation, from model design to hardware optimization, drastically reduces the time from idea to production. While initially developed for ads ranking, KernelEvolve is designed for broad applicability to any AI model that requires custom kernel performance, making it a versatile tool in Meta's AI infrastructure stack.
Related Articles
- 8 Key Insights into Meta's AI-Powered Efficiency Engine at Hyperscale
- BleachBit’s TUI: Interactive Cleaning for Headless and Lightweight Systems
- Ubuntu's Ordeal Continues: Twitter Account Hijacked After DDoS Assault
- Top 10 Highlights of Fedora KDE Plasma Desktop 44
- 7 Essential Steps to Rebase Your Fedora Silverblue to Fedora Linux 44
- 10 Key Highlights of Fedora Asahi Remix 44 for Apple Silicon Macs
- AI-Powered Bug Hunting: How Greg Kroah-Hartman Is Revolutionizing Linux Kernel Security
- Meta's AI Agent 'KernelEvolve' Slashes Infrastructure Optimization from Weeks to Hours